

Insider Brief
- Large Language Models (LLMs) have rapidly become integral to various applications, from programming assistants to chatbots.
- One of these model’s challenges is ensuring that all client requests are processed fairly and efficiently.
- Researchers propose an algorithm — called a Virtual Token Counter (VTC) — to achieve fairness in serving by using a cost function that accounts for the number of words and responses that are processed.
Large Language Models (LLMs) — like ChatGPT and BARD — have rapidly become integral to a range of applications, from programming assistants to chatbots. However, their rise has introduced new challenges, particularly in ensuring that all client requests are processed fairly and efficiently. A research paper recently published on the pre-print server ArXiv delves into these challenges and gives an outline of a virtual token counter — which is explained below — as one possible solution to improve the fairness and resource efficiency of these LLM inference services.
The Problem of Fairness and Resource Utilization
LLM inference services, which handle requests ranging from brief chats to extensive document analyses, must maintain fairness to prevent any single client from monopolizing resources. Most major LLM services impose request rate limits to ensure fairness. However, this method isn’t the best use of resources and can lead to customer complains when there is spare capacity.
As the researchers mention in the paper: “While there is a rich literature on fair scheduling, serving LLMs presents new challenges due to their unpredictable request lengths and unique batching characteristics on parallel accelerators.”
The traditional First-Come-First-Serve (FCFS) scheduling method commonly used by LLM systems, though simple, has significant drawbacks, as well. For instance, a client sending a disproportionate number of requests can slow down the service for all other clients. To mitigate this, many services rely on another type of request limit, called a request-per-minute (RPM) limits.
Yet, as the researchers note: “RPM can lead to low resource utilization. A client sending requests at a high rate will be restricted even if the system is underutilized, leading to wasted resources.”
Fairness is Unfair to LLMs?
LLM services struggle with implementing fair scheduling due to its unique challenges. One significant challenge is defining fairness in the context of LLM serving, which differs from traditional fairness concepts in networking and operating systems. Traditional fairness measures the cost of requests as a fixed value, which is relatively easy to estimate. However, in LLM serving, the cost per token can vary significantly. Input tokens are typically processed in parallel, whereas output tokens must be generated sequentially, making them more resource-intensive.
The team also adds the server’s variable token-rate capacity and the unknown output length of requests pose further challenges.
They write: “Without knowing the length in advance, traditional algorithms like SFQ and Deficit Round Robin (DRR) cannot determine how many jobs can be scheduled within the quantum (of service).”
The researchers conducted extensive experiments to validate the performance of the VTC algorithm. The results demonstrated the superior performance of VTC in ensuring fairness compared to other baseline methods, which exhibited shortcomings under various conditions.
“Through extensive experiments, we demonstrate the superior performance of VTC in ensuring fairness, especially in contrast to other baseline methods,” the researchers write.
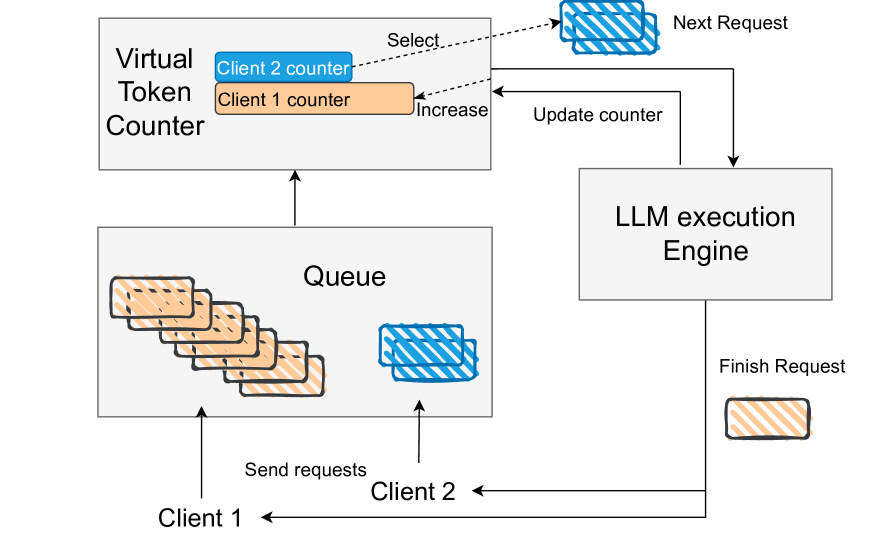
Virtual Token Counter
To address these issues, the researchers propose a novel scheduling algorithm called the Virtual Token Counter (VTC). This algorithm aims to achieve fairness in serving by using a cost function that accounts for the number of input and output tokens processed. Maybe an easier way to put it: the system is designed to ensure fairness by considering the number of words and responses processed for each user request.
The researchers write: “VTC tracks the services received for each client and will prioritize the ones with the least services received, with a counter lift each time a client is new to the queue. This counter lift fills the gap created by a low load period of the client, ensuring fairness.”
Broader Implications for LLM Serving Systems
This research not only addresses fairness but also bridges a critical gap in LLM serving systems.
While well-known techniques like advanced batching mechanisms, memory optimizations and GPU kernel optimizations have improved LLM performance, none have considered fairness among clients, according to the team.
They add that the proposed VTC algorithm could be integrated with many of these techniques, further enhancing their effectiveness.
The researchers conclude with a recognition the client needs to be in the loop to improve services. And, as competition among the LLMs heats up, these services will look for ways to improve market share, client service will be an important consideration. Client service and fairness will be part of those efforts.
“We studied the problem of fair serving in Large Language Models (LLMs) with regard to the service received by each client. We identified unique characteristics and challenges associated with fairness in LLM serving, as compared to traditional fairness problems in networking and operating systems. We then defined what constitutes fairness and proposed a fair scheduler, applying the concept of fair sharing to the domain of LLM serving at the token granularity.”
The research team includes: Ying Sheng from UC Berkeley and Stanford University, along with Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, and Joseph E. Gonzalez, all from from UC Berkeley, and Danyang Zhuo from Duke University.
This article attempts to summarize VTC and their findings, but for a deeper dive please read the paper.


