
Insider Brief
- What is Multi-Token Prediction — Meta researchers have introduced a new training method called multi-token prediction.
- MTP changes the approach by asking the model to predict multiple future words simultaneously instead of just one.
- The approach aims to address these inefficiencies and improve the performance of those traditional language models.
Large language models — LLMs — have made impressive strides generating human-like text and perform various language tasks, but they are traditionally trained using a method called next-token prediction. This method involves predicting the next word in a sequence based on the words that come before it. While effective, this approach still suffers from inefficiencies, including a strain on computational resources for memory and processing power.
In a paper on the pre-print server ArXiv, researchers at Meta have introduced a new training method called multi-token prediction. The researchers report that this new approach aims to address these inefficiencies and improve the performance of those traditional language models.
The paper also can serve as a tutorial of what Multi-Token Prediction is and how it might lead to better large language models — LLMs — for example ChatGPT and Meta’s own Llama.
What Is Multi-Token Prediction — Understanding MTP
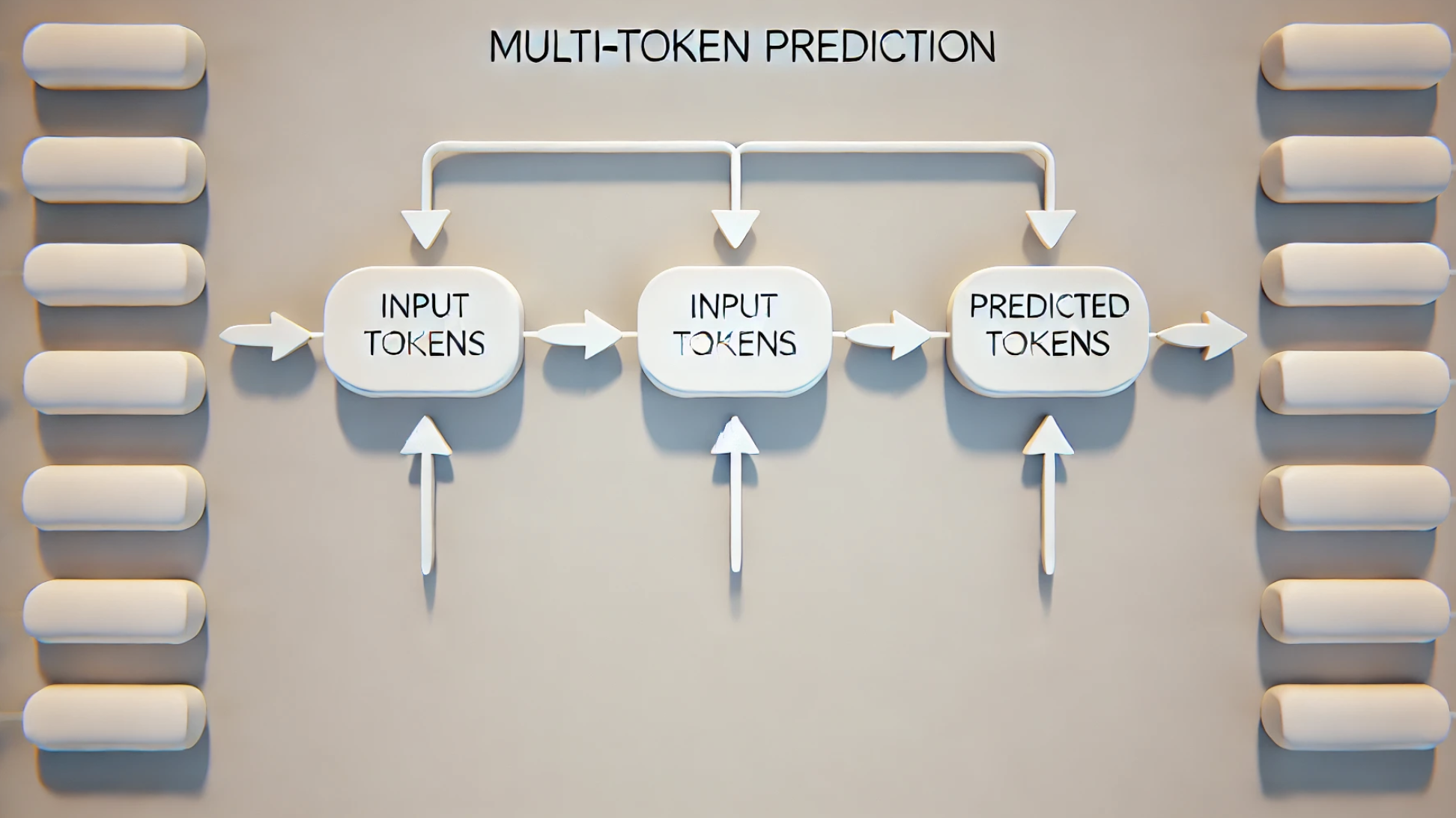
The traditional approach in language models, known as next-token prediction, involves predicting the next word in a sequence based solely on the preceding words, generating text one token at a time.
Multi-token prediction, however, is different — it changes the approach by asking the model to predict multiple future words simultaneously instead of just one. At each position in a sentence, the model predicts the next several words at once, using multiple prediction pathways, or “heads,” all working together.
This method, as reported by Meta researchers, improves how efficiently the model learns without needing extra training time or memory.
Methodology
The core idea behind multi-token prediction is to train the model to predict a sequence of future words from each position in the training data, rather than just the next word. This approach uses a shared underlying structure, called a transformer trunk, to understand the context, and then uses multiple independent prediction heads to guess the future words in parallel.
“At each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk,” the researchers explain.
Advantages and Performance Improvements
According to the researchers, Multi-token prediction offers several advantages, which, then could lead to further innovations that rely on LLMs. Some of the improvements:
Better Learning Efficiency: Multi-token prediction helps the model learn more effectively from the same amount of data. This is especially beneficial for larger models and remains effective even with extended training periods. For example, a 13-billion parameter model trained with multi-token prediction solved 12% more problems on a coding test and 17% more on another benchmark compared to models using the traditional next-token method.
Improved Generative Performance: On tasks that require generating new content, such as writing code, models trained with multi-token prediction consistently outperformed other strong models by a significant margin. This is because the model can better capture and predict long-term patterns in the data.
Faster Inference: Another major benefit is the speed at which these models can make predictions. Models trained with multi-token prediction were found to be up to three times faster at making predictions, even when handling large amounts of data. This is particularly useful in real-world applications where speed and efficiency are crucial.
Experimental Validation
Researchers conducted extensive experiments to validate the benefits of multi-token prediction across various model sizes and tasks:
First, there are benefits in scaling, the researchers report. Multi-token prediction can become more pronounced as the size of the model increases. Tests on models ranging from 300 million to 13 billion parameters showed that larger models saw more significant performance improvements, the researchers report. This suggests that multi-token prediction is especially beneficial for very large language models.
The team adds that the method enhances algorithmic reasoning. On smaller, more technical tasks, models trained with multi-token prediction showed improved ability to understand and apply complex rules and patterns. This means they are better at tasks that require logical thinking and problem-solving.
Finally, memory efficiency — which, as discussed, is one of the main drawbacks of sequential based systems — can be improved in multi-token prediction. Training models to predict multiple words at once could potentially use more computer memory, which is a concern. However, the researchers optimized the training process to keep memory usage manageable, ensuring the method remains efficient.
Limitations
Some of the bugs of Multi-token prediction will need to be worked out. For example, some researchers indicate that, because it processes multiple tokens independently or in parallel, Multi-token processing can struggle with understanding context. This might lead to missing nuances and relationships between words that are crucial for accurate comprehension. Designing models — ones that can efficiently handle multi-token processing without compromising on accuracy — can be complex. Another issue: Effective multi-token processing often requires huge amounts of training data to learn the nuances of language patterns accurately.
Future Directions
The researchers suggest that the introduction of multi-token prediction is a significant advance in the training of large language models. By improving learning efficiency and performance across various tasks without additional computational costs, this method holds promise for enhancing the capabilities of language models in both language and coding tasks.
In the future, the researchers will focus on optimizing parameters, improving techniques and enhancing efficiency to maximize performance in prediction tasks.
They write: “In future work, we would like to better understand how to automatically choose nn in multi-token prediction losses. One possibility to do so is to use loss scales and loss balancing. Also, optimal vocabulary sizes for multi-token prediction are likely different from those for next-token prediction, and tuning them could lead to better results, as well as improved trade-offs between compressed sequence length and compute-per-byte expenses. Finally, we would like to develop improved auxiliary prediction losses that operate in embedding space.”


