
Insider Brief
- Mistral has announced the release of Mistral NeMo in collaboration with NVIDIA.
- The team says it is a cutting-edge 12 billion parameter model that is pushing the boundaries of AI capabilities.
- Mistral NeMo features large context window, capable of handling up to 128k tokens.
Mistral has announced the release of Mistral NeMo, what they’re calling a cutting-edge 12 billion parameter model developed in collaboration with NVIDIA. Designed to push the boundaries of AI capabilities, Mistral NeMo promises state-of-the-art reasoning, world knowledge, and coding accuracy within its size category.
The Mistral blog provides detailed insights into the features and benefits of this new model, underscoring its potential for both research and enterprise applications.
Key Features and Advantages
Mistral NeMo features large context window, capable of handling up to 128k tokens. This added capacity allows for more complex and nuanced interactions, making it particularly effective in applications requiring extensive context, such as multilingual communication and intricate coding tasks.
“Mistral NeMo is built on a standard architecture, making it an easy drop-in replacement for systems currently using the Mistral 7B model,” the blog states.
This compatibility simplifies the integration process for users looking to upgrade their existing AI systems without the need for extensive modifications.
Pre-trained Checkpoints and Licensing
Mistral wants this model to be used widely, so the company released both pre-trained base and instruction-tuned checkpoints under the Apache 2.0 license. As an explainers: A pre-trained base model is an AI model that has been initially trained on a large, diverse dataset to learn general language patterns. An instruction-tuned checkpoint is a version of this model that has undergone additional fine-tuning on specific tasks to improve its performance and accuracy for particular applications.
This open-source approach is designed to encourage innovation and accessibility, providing researchers and enterprises with robust tools to advance their projects.
“Mistral NeMo was trained with quantization awareness, enabling FP8 inference without any performance loss,” according to the blog. This aspect of the model ensures efficient processing and high performance, even when handling complex tasks.
Comparative Performance
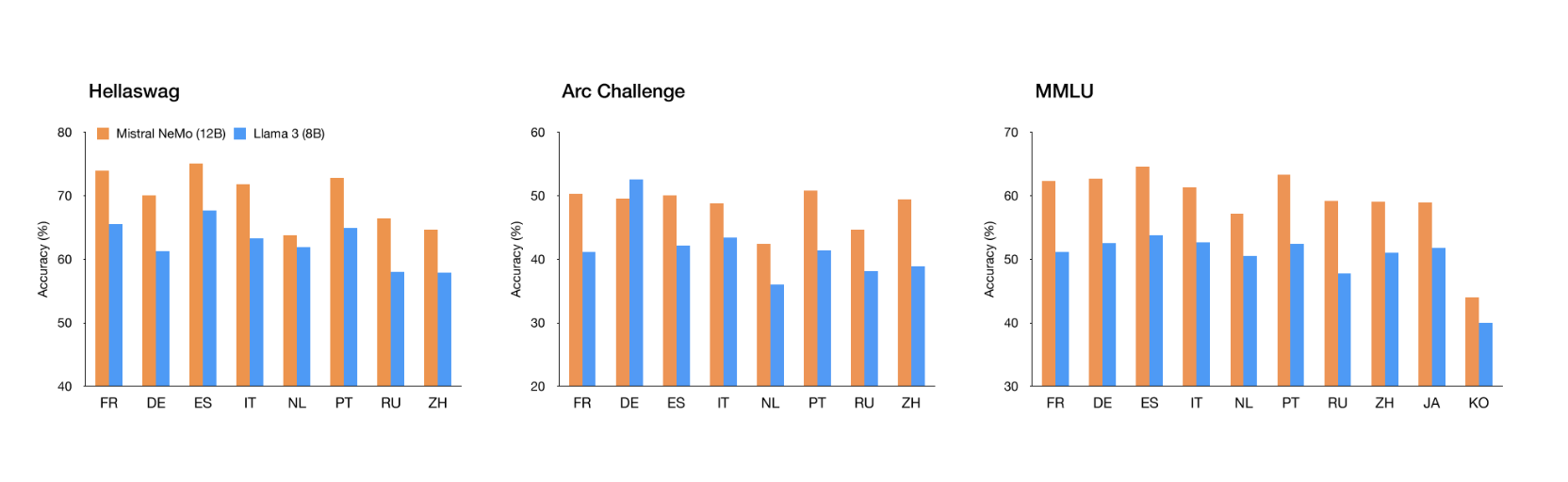
In terms of performance, Mistral NeMo stands out when compared to other recent open-source pre-trained models, such as Gemma 2 9B and Llama 3 8B. The model demonstrates superior accuracy and efficiency, particularly in multilingual applications.
“Mistral NeMo excels in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic and Hindi,” according to the blog post.
This multilingual proficiency is crucial for global applications, enabling more inclusive and comprehensive AI interactions across different languages and cultures.
Tekken Tokenizer Efficiency
Mistral NeMo also introduced the Tekken tokenizer — another innovation. Based on Tiktoken, this new tokenizer was trained on over 100 languages and is notably more efficient than the previous SentencePiece tokenizer. Tekken compresses natural language text and source code more effectively, offering approximately 30% better compression rates for languages like Chinese, Italian, French, German, Spanish, and Russian.
It also delivers 2x and 3x better compression for Korean and Arabic, respectively.
“Compared to the Llama 3 tokenizer, Tekken proved to be more proficient in compressing text for approximately 85% of all languages,” the blog reports. This enhanced efficiency is critical for optimizing storage and processing resources, particularly in large-scale AI applications.
Mistral NeMo has undergone extensive fine-tuning and alignment, resulting in improved performance over the previous Mistral 7B model. It excels in following precise instructions, reasoning, managing multi-turn conversations, and generating code, making it a powerful tool for a wide range of applications.
Accessibility and Integration
For those interested in exploring the capabilities of Mistral NeMo, the model’s weights are available on HuggingFace for both the base and instruction-tuned versions. Users can experiment with Mistral NeMo through mistral-inference and adapt it with mistral-finetune. The model is also accessible on la Plateforme under the name open-mistral-nemo-2407 and is packaged as an NVIDIA NIM inference microservice, available from ai.nvidia.com.


