
Insider Brief
- Microsoft researchers have developed a new AI evaluation method that aims to predict and explain model performance on unfamiliar tasks.
- ADeLe assesses 18 types of cognitive and knowledge-based abilities, creating detailed ability profiles that reveal strengths, weaknesses, and performance thresholds across large language models.
- The method achieved 88% accuracy in predicting task success for models like GPT-4o and LLaMA-3.1-405B and could serve as a tool for evaluating AI in policy, security, and multimodal systems.
A new evaluation method developed by Microsoft researchers aims to predict and explain how artificial intelligence (AI) models will perform on unfamiliar tasks, offering a detailed look into their strengths and weaknesses and paving the way for more transparent and reliable AI deployments.
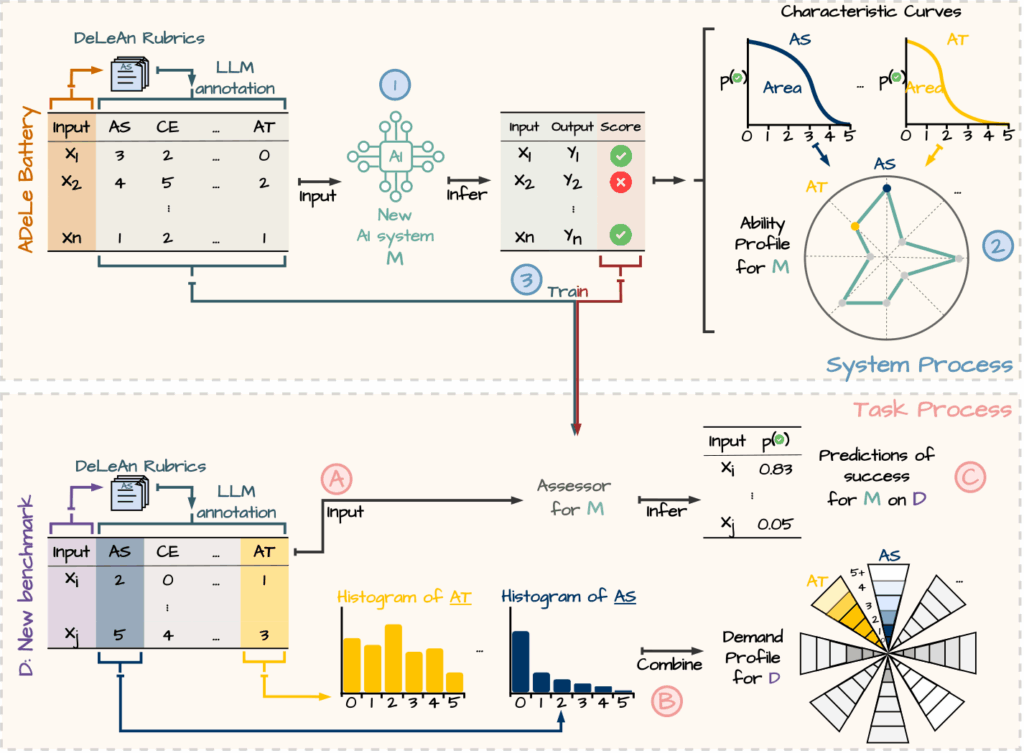
The method, introduced in a study led by Lexin Zhou and Xing Xie and supported by Microsoft’s Accelerating Foundation Models Research grant program, centers on a framework called ADeLe (annotated-demand-levels), the company announced in a blog post. Unlike traditional benchmarks that measure overall accuracy, ADeLe applies the measurement scales of 18 types of cognitive and knowledge-based abilities required by specific tasks. It then compares those demands with a model’s capabilities to forecast outcomes.
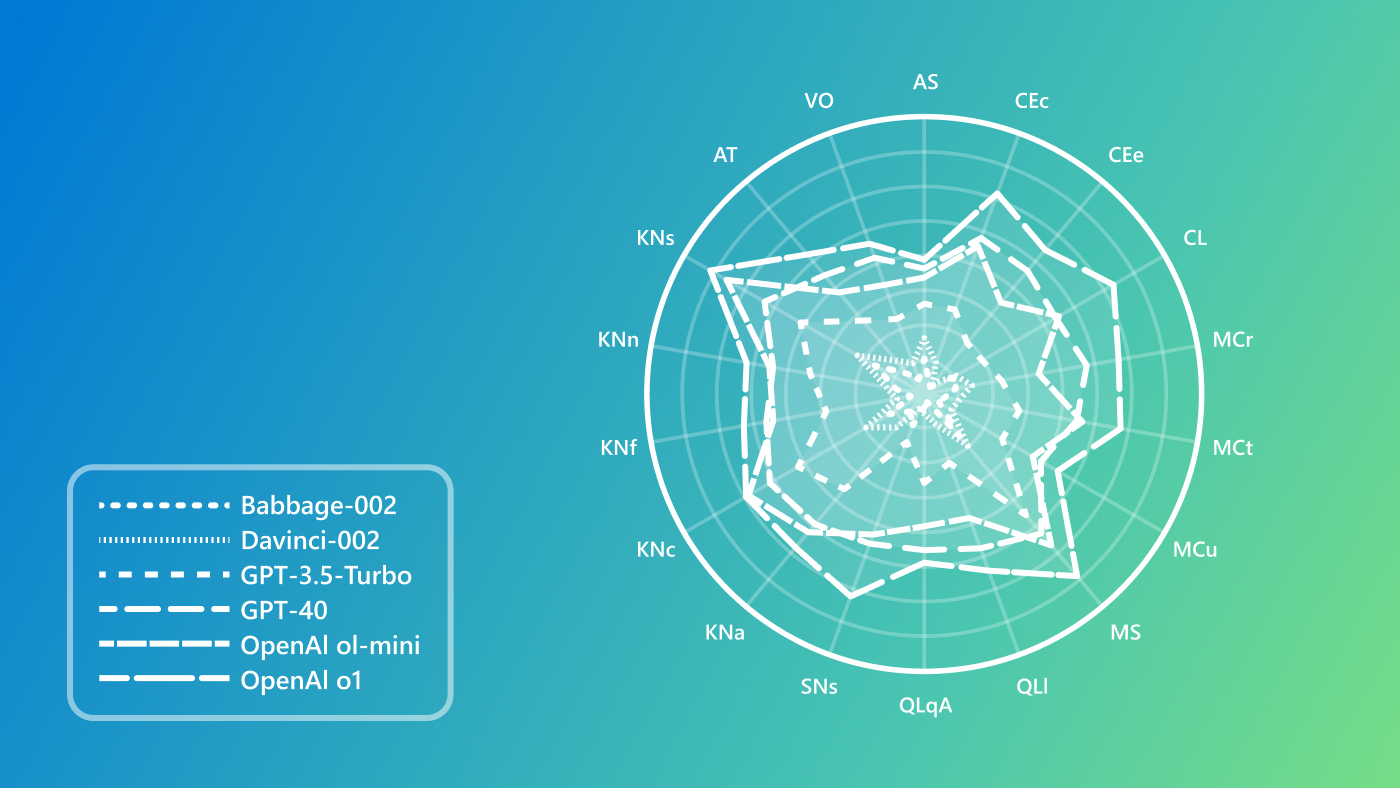
The paper titled “General Scales Unlock AI Evaluation with Explanatory and Predictive Power,” outlines the method that applies a scoring system from 0 to 5 for each of the 18 dimensions, including attention, reasoning, and domain-specific knowledge. Originally created for human evaluations, these rubrics were adapted to AI and shown to be consistent when applied by the models themselves, according to researchers. By analyzing 16,000 examples from 63 tasks across 20 AI benchmarks, the team created ability profiles for 15 large language models (LLMs).
The findings, Microsoft points out, highlight three central insights. First, many existing AI benchmarks fail to test what they intend. For example, the Civil Service Examination benchmark, assumed to measure logical reasoning, also draws heavily on specialized knowledge and metacognition. The TimeQA benchmark only includes questions of moderate difficulty, limiting its usefulness in assessing true model range.
Second, the ability profiles created with ADeLe reveal meaningful patterns in model behavior. Each profile is based on the difficulty level at which a model achieves a 50% success rate for a given ability. The researchers plotted subject characteristic curves for each ability, uncovering performance thresholds and documenting how ability varies by model architecture, training, and scale. The results show that newer LLMs generally perform better, but not universally across all abilities. The reseachers report that gains are especially evident in reasoning and abstraction but taper off beyond a certain model size.
Third, ADeLe can predict how models will perform on new, unseen tasks. The prediction system, which matches task demands with model abilities, achieved around 88% accuracy on well-known models like GPT-4o and LLaMA-3.1-405B. This exceeds the performance of traditional evaluation methods and offers a way to anticipate failures before deployment.
The researchers report seeing broad applications for ADeLe. Beyond text-based LLMs, the framework could be adapted for evaluating multimodal and embodied AI systems. They also suggest that ADeLe could serve as a standardized tool for government and industry bodies developing AI policy, security protocols, or research roadmaps.
Microsoft added in the post that the study contributes to a growing body of work urging the adoption of psychometric-style evaluation for AI. It aligns with recent white papers advocating for more rigorous, scalable, and interpretable evaluation systems as general-purpose AI capabilities outpace existing benchmarks. Microsoft researchers aim to establish a collaborative community to refine and expand ADeLe as an open standard.
“As general-purpose AI advances faster than traditional evaluation methods, this work lays a timely foundation for making AI assessments more rigorous, transparent, and ready for real-world deployment,” the Microsoft team noted. “The research team is working toward building a collaborative community to strengthen and expand this emerging field.”




