Insider Brief
- Chinese AI company Z.ai has released two new language models, GLM-4.5 and GLM-4.5-Air, designed to handle reasoning, coding, and autonomous task execution through a unified system.
- The models use a Mixture of Experts architecture to balance high performance with computational efficiency, operating in both “thinking” and “non-thinking” modes to optimize complex problem-solving and rapid response tasks.
- Benchmarked against global leaders, GLM-4.5 ranked third overall and outperformed several larger models in areas like web browsing, math reasoning, and agentic coding, while remaining accessible through open-source licenses and competitive pricing.
Chinese AI firm Z.ai has launched two new language models, GLM-4.5 and GLM-4.5-Air, which combine reasoning, coding, and autonomous task-handling into a single system, according to a company blog post.
The launch could signal a step toward artificial intelligence (AI) that could rival leading global models. The models aim to address the growing demand for AI that can handle complex, multi-step tasks across various domains, from software development to web browsing, while maintaining efficiency and accessibility.
Perhaps reading between the lines, the company suggests this is a step toward artificial general intelligence.
“LLM always targets at achieving human-level cognitive capabilities across a wide range of domains, rather than designed for specific tasks. As a good LLM model, it is necessary to deal with general problem solving, generalization, commen sense reasoning, and self-improvement,” the team writes. “In the past five years, OpenAI’s GPT-3 learns commen-sense knowledge, and o1 uses reinforcement learning to think before respond, significantly improving reasoning skills in coding, data analysis, and complex math. However, the resultant models are still not really general: some of them are good at coding, some good at math, and some good at reasoning, but none of them could achieve the best performance across all the different tasks. GLM-4.5 makes efforts toward the goal of unifying all the different capabilities.”
355 Billion Total Parameters
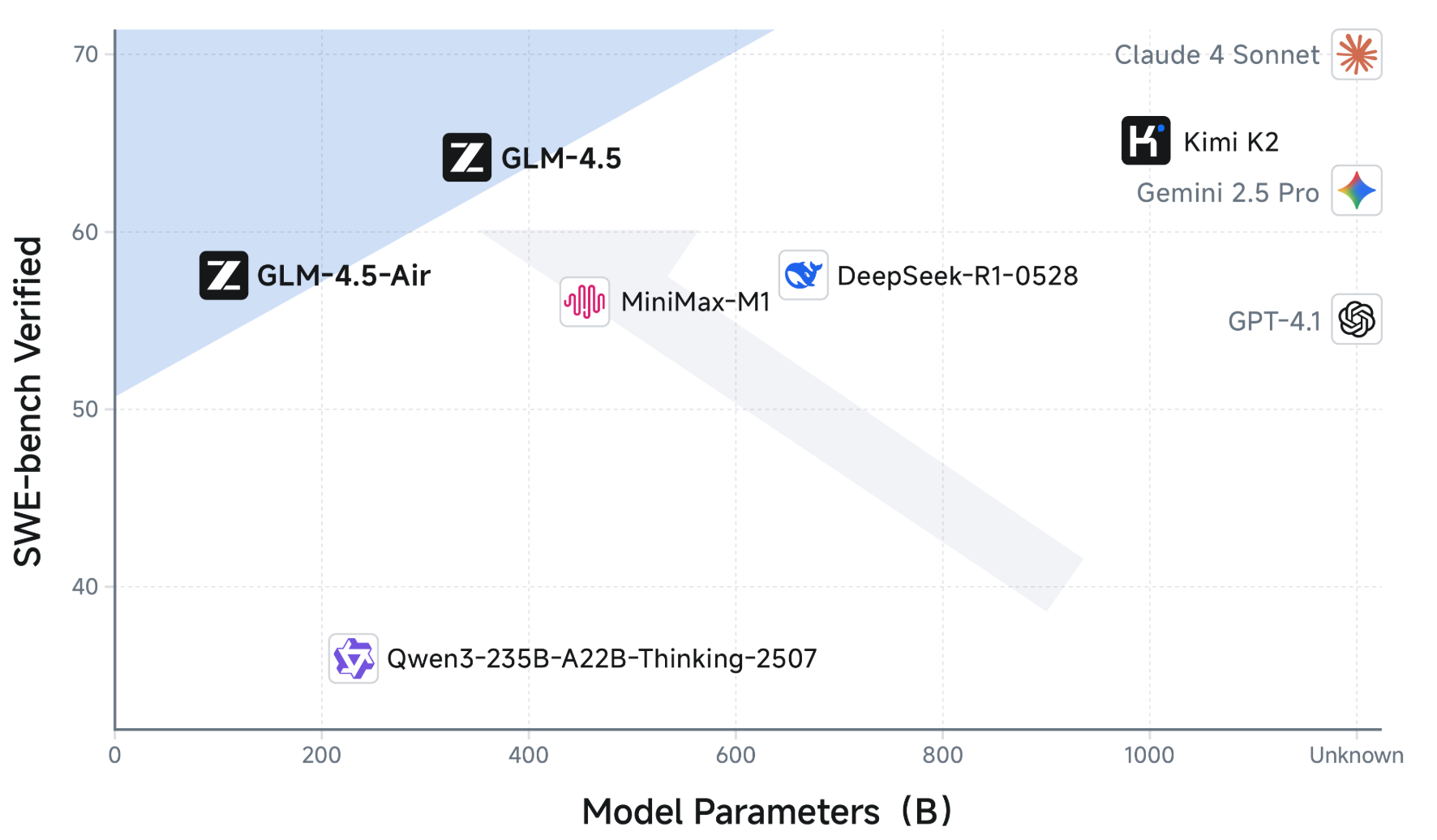
The flagship GLM-4.5, with 355 billion total parameters but only 32 billion active at any time, and its lighter counterpart, GLM-4.5-Air, with 106 billion total and 12 billion active parameters, are designed to perform tasks that typically require specialized AI systems. Unlike earlier models that excel in narrow areas like coding or math, these models unify multiple capabilities, making them suitable for applications requiring both quick responses and deep problem-solving. According to Z.ai’s announcement, this unification tackles a key limitation of large language models: the inability to excel across diverse tasks simultaneously, according to the blog.
Both models operate in two modes. A “thinking mode” handles complex reasoning and tool use, such as navigating web browsers or generating code, while a “non-thinking mode” provides instant answers for simpler queries, according to the post. This dual approach allows the models to balance speed and depth, catering to varied real-world needs. For instance, a developer might use the thinking mode to build a full website, while a customer service agent could rely on the non-thinking mode for rapid responses.
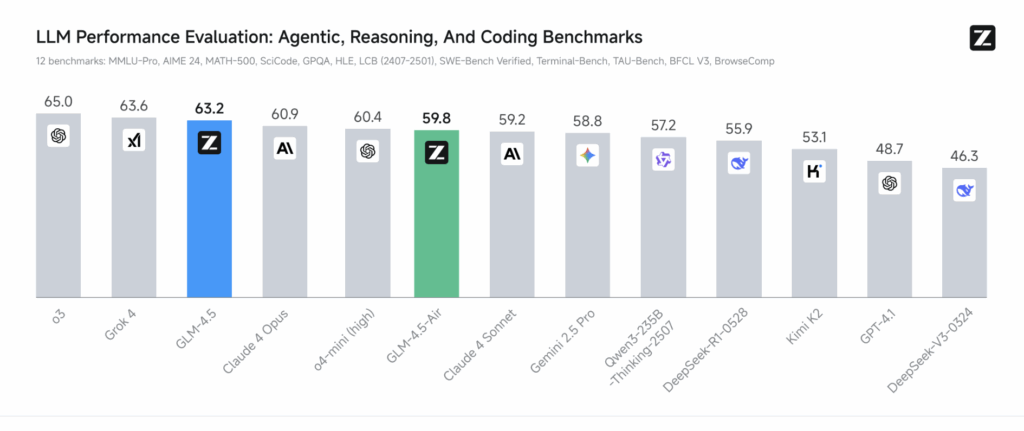
Z.ai’s models were evaluated against industry leaders, including OpenAI’s GPT-4.1, Anthropic’s Claude 4 Sonnet and Google DeepMind’s Gemini 2.5 Pro, across 12 benchmarks testing reasoning, coding, and agentic tasks, which are activities where AI autonomously interacts with tools or environments. GLM-4.5 ranked third overall, behind only OpenAI’s o3 and xAI’s Grok 4, while GLM-4.5-Air placed sixth, outperforming many models with larger parameter counts.
These results, detailed in Z.ai’s blog, highlight the models’ efficiency, achieving high performance with fewer computational resources.
Task Ranks
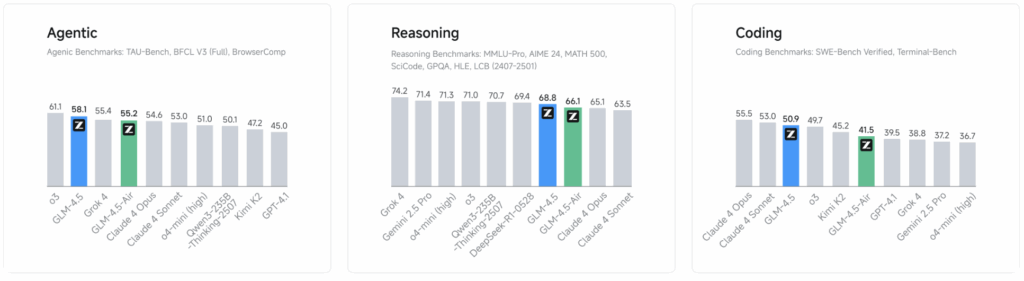
In agentic tasks, which involve AI acting independently, GLM-4.5 matches Claude 4 Sonnet’s performance on benchmarks like TAU-bench and Berkeley Function Calling Leaderboard v3. It excels in web browsing, a task requiring multi-step reasoning and tool use. On the BrowseComp benchmark, GLM-4.5 correctly answered 26.4% of complex questions, surpassing Claude 4 Opus’s 18.8% and nearing OpenAI’s o4-mini-high at 28.3%. This capability, Z.ai notes, stems from the models’ ability to process up to 128,000 tokens—roughly 300 pages of text—in a single prompt, enabling them to handle extended interactions without losing context.
For reasoning, GLM-4.5 performs strongly in mathematics, science, and logic. It scored 98.2% on the MATH 500 benchmark, competitive with OpenAI’s o3 at 99.2%, and 91.0% on AIME24, a math test for high school students. These scores, validated by automated systems, reflect the model’s ability to tackle complex problems under its thinking mode, which mimics human-like deliberation.
Coding is another strength. GLM-4.5 can build entire web applications, including front-end interfaces, databases, and back-end systems, with results that align with human design preferences. On the SWE-bench Verified benchmark, it scored 64.2%, outperforming GPT-4.1’s 48.6% and rivaling Claude 4 Sonnet’s 70.4%. Z.ai tested its agentic coding against Claude 4 Sonnet, Alibaba’s Qwen3-Coder, and Moonshot’s Kimi K2 across 52 tasks, achieving a 53.9% win rate over Kimi K2 and 80.8% over Qwen3-Coder. Its 90.6% tool-calling success rate, the highest among competitors, underscores its reliability in coding tasks.
Mixture of Experts
The models’ efficiency comes from their Mixture of Experts (MoE) architecture, which activates only a fraction of parameters during processing, reducing computational demands. GLM-4.5 uses 96 attention heads and a deeper layer structure, enhancing reasoning without increasing training costs. Z.ai’s proprietary reinforcement learning system, dubbed “slime,” further optimizes training by separating data generation from model updates, ensuring high GPU utilization. This system, open-sourced for community use, supports both synchronous and asynchronous training, addressing bottlenecks in agentic tasks where data collection can be slow.
Beyond technical prowess, GLM-4.5 and GLM-4.5-Air are accessible. Their weights are available on HuggingFace and ModelScope under the MIT license, allowing commercial use and local deployment. Z.ai’s API, compatible with OpenAI’s, offers pricing as low as $0.11 per million input tokens, undercutting competitors like DeepSeek’s R1. The models also support creative tasks, such as generating PowerPoint slides or interactive games like Flappy Bird, showcasing their versatility.
Z.ai’s release, backed by investors like Alibaba and Tencent, positions it as a leader in China’s AI race, which has seen 1,509 language models launched by July 2025. The models’ performance, affordability, and open-source nature could challenge Western dominance in AI, though Z.ai’s place on the U.S. entity list may limit its global reach. As enterprises seek cost-effective, adaptable AI, GLM-4.5’s unified capabilities signal a shift toward more integrated, autonomous systems.