
Insider Brief
- Researchers at Tokyo University of Science developed HEAPGrasp, a vision-based system that enables robots to grasp transparent and reflective objects using RGB images instead of traditional depth sensing.
- The system combines semantic segmentation with silhouette-based 3D reconstruction and uses a deep learning model to optimize camera movement for faster and more accurate grasping.
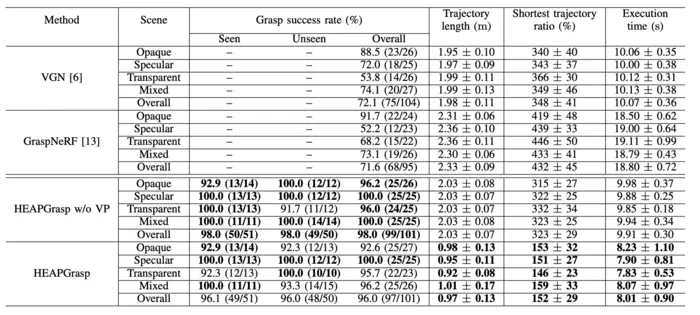
- The study, published in IEEE Robotics and Automation Letters, reported a 96% success rate while reducing camera movement by 52% and execution time by 19%, though testing was conducted in controlled environments.
Researchers at Tokyo University of Science have developed a vision-based method that allows robots to reliably grasp transparent and reflective objects, addressing a key limitation in robotic manipulation. The work, supported by JSPS KAKENHI and JKA, introduces HEAPGrasp, a system that replaces traditional depth sensing with RGB image-based perception to improve object detection and handling across challenging materials, according to the university.
“Traditionally, transparent or mirrored (glossy) objects such as reflective metal parts, transparent trays have been unstable to detect when using depth sensors or conventional 3D measurement techniques, making automatic grasping by robots difficult and ultimately leading to human intervention,” noted Department of Mechanical and Aerospace Engineering at Tokyo University of Science Associate Professor Shogo Arai. Aria noted their approach is based on the theory that that accurate grasping is possible even when depth information is unreliable, as long as object contours can be consistently identified.
How Does HEAPGrasp Work?
HEAPGrasp is built on a combination of semantic segmentation and silhouette-based 3D reconstruction. Using a single hand-eye RGB camera, the system captures images from multiple viewpoints and isolates object contours. It then reconstructs object shape using a Shape from Silhouette method, which estimates 3D geometry based on overlapping silhouettes rather than depth data. A deep learning-based planning model determines the most efficient camera positions, balancing accuracy with speed and minimizing unnecessary motion.
The study, published in IEEE Robotics and Automation Letters, reports a 96% grasp success rate across environments containing transparent, opaque and specular objects, while also reducing camera movement by 52% and execution time by 19% compared with baseline methods. Researchers said these improvements suggest a more efficient and scalable approach to robotic material handling, particularly in industries such as manufacturing, logistics and food service where object variability has limited automation.
The researchers evaluated the system across 20 scenarios with mixed object types and benchmarked it against existing grasping methods. While the results demonstrate strong performance, the experiments were conducted in controlled settings, and further validation will be needed in more dynamic, unstructured environments.
“Our approach achieves accurate 3D measurement of objects while minimizing camera movement and execution time,” noted researcher Ginga Kennis. “By reducing the amount of pre-adjustment required, HEAPGrasp simplifies on-site implementation and operation, especially since it can be retrofitted to existing robotic systems.”
Image credit: Associate Professor Shogo Arai from Tokyo University of Science, Japan


