
Insider Brief
- Robbyant, the embodied AI unit within Ant Group, open-sourced LingBot-Map, a streaming 3D reconstruction model that enables real-time spatial mapping using standard RGB cameras
- The model performs continuous, frame-by-frame scene reconstruction and camera tracking, achieving improved accuracy across benchmarks while running at about 20 FPS and supporting long-duration inference
- Ant Group said LingBot-Map is part of a broader embodied AI stack, alongside models for depth, vision-language-action and simulation, aimed at supporting real-time perception and decision-making in robotics
Robbyant, the embodied AI unit within Ant Group, has open-sourced LingBot-Map, a streaming 3D reconstruction model designed to enable robots and other systems such as autonomous vehicles and AR devices to map and understand their surroundings in real time using a standard RGB camera.
According to Ant Group, unlike traditional approaches that process images offline, LingBot-Map operates continuously, estimating camera position and reconstructing 3D scenes frame-by-frame as video is captured. The system is designed for applications requiring real-time spatial awareness, including robot navigation, obstacle avoidance and object manipulation.
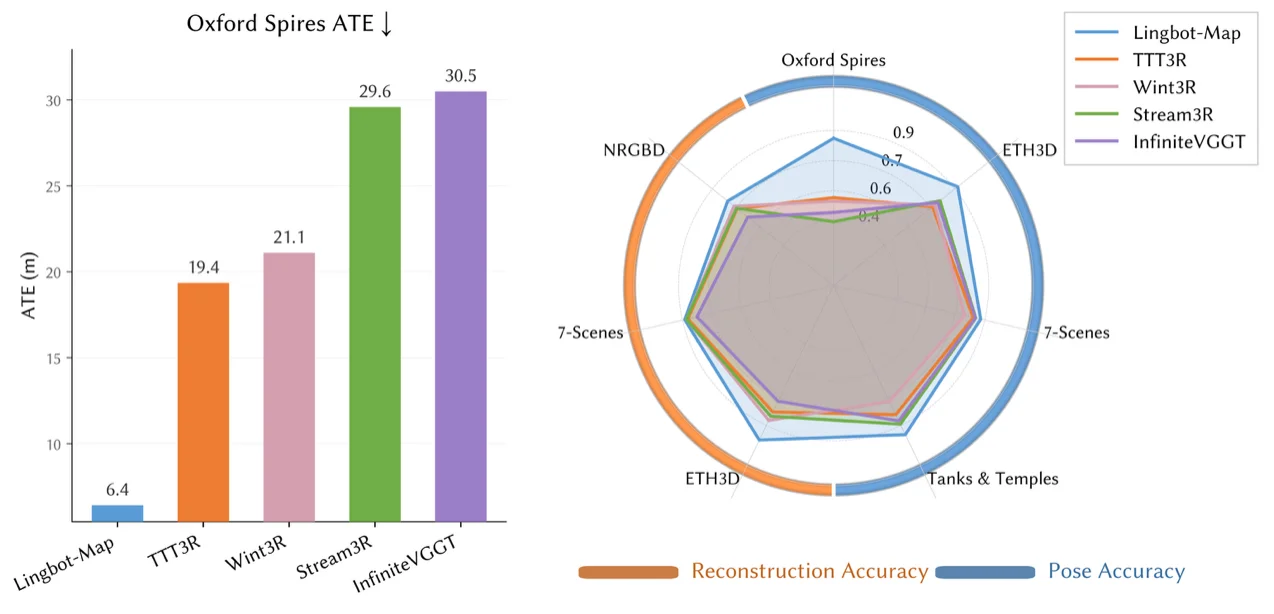
Ant Group said the model improves trajectory accuracy and reconstruction quality across multiple benchmarks. On the Oxford Spires dataset, LingBot-Map achieved an Absolute Trajectory Error of 6.42 meters, outperforming both prior streaming methods and several offline approaches. The model also showed strong performance on ETH3D, 7-Scenes and Tanks and Temples benchmarks, including a reconstruction F1 score of 98.98 on ETH3D.
The system runs at approximately 20 frames per second and supports long-duration inference across video sequences exceeding 10,000 frames while maintaining stable accuracy. This allows continuous operation in dynamic environments without requiring batch processing.
LingBot-Map uses an auto-regressive architecture built on a Geometric Context Transformer, designed to balance accuracy, consistency and computational efficiency. A key component, referred to as Geometric Context Attention, organizes spatial information across frames to maintain context while reducing redundant computation.
The release is part Robbyant’s efforts to build a software stack for embodied AI. The Chinese company has also open-sourced related models, including systems for depth perception, vision-language-action tasks, world simulation and video-based robot control.
Image credit: Ant Group


