
Insider Brief
- The latest Flash Attention iteration is designed to help change how AI systems process information and promote faster and more efficient AI applications.
- Flash Attention 3 builds upon its predecessors to tackle one of the most persistent bottlenecks in AI processing: the attention mechanism in transformer models.
- In tests using FP16 (16-bit floating-point) precision, Flash Attention 3 achieved speeds of up to 740 teraflops per second on an H100 GPU.
A new algorithm promises to significantly accelerate the performance of large language models (LLMs), according to a team of researchers.
Noted AI researcher Tri Dao, of Princeton and Together AI, writes in his blog that the latest iteration of Flash Attention can help change how AI systems process information — and that could one day lead to faster and more efficient AI applications across various industries. He adds that Flash Attention 3 builds upon its predecessors to tackle one of the most persistent bottlenecks in AI processing: the attention mechanism in transformer models.
A transformer is a type of neural network architecture used in machine learning that relies on self-attention mechanisms — meaning it can highlight important parts of a data sequence — to process and understand that sequential data, like words in a sentence. This allows it to handle long-range dependencies in text more effectively than previous models.
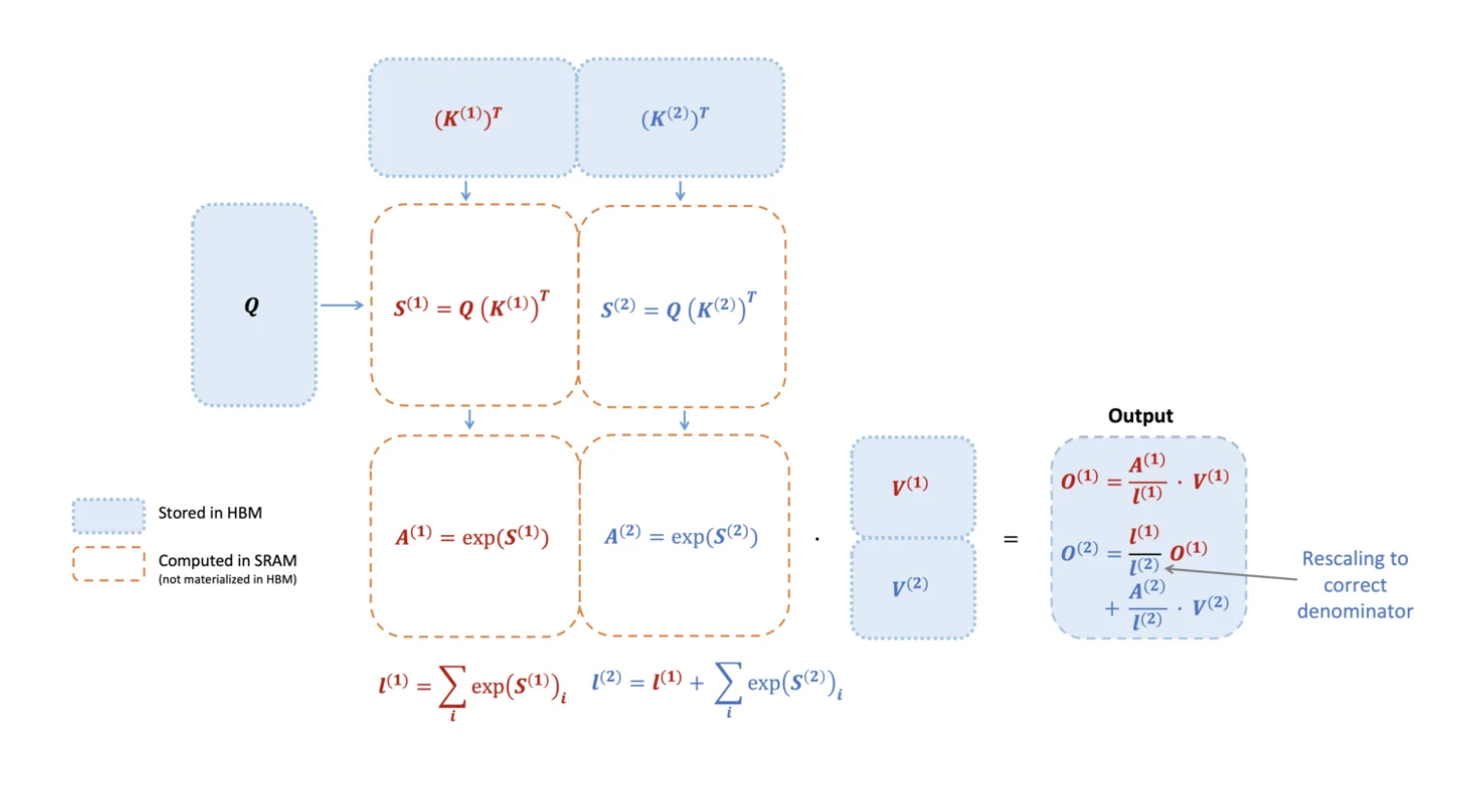
While the attention mechanism allows AI models to focus on relevant parts of input data when making predictions, the process becomes increasingly time-consuming and resource-intensive as models grow larger and handle longer sequences of text.
Flash Attention 3 addresses this challenge by optimizing how GPUs (Graphics Processing Units) handle the attention computation. The new algorithm takes advantage of recent advances in GPU hardware, particularly those found in NVIDIA’s Hopper architecture.
According to Dao’s post and a paper that the research team published on ArXiv, a pre-print server, key improvements in Flash Attention 3 include:
Better GPU utilization: The algorithm now uses up to 75% of an H100 GPU’s maximum capabilities, a significant jump from the 35% utilization of its predecessor. This translates to processing speeds 1.5 to 2 times faster than previous versions.
Enhanced low-precision performance: Flash Attention 3 can work effectively with lower precision numbers (FP8) while maintaining accuracy. This allows for even faster processing and potentially lower memory usage, which could lead to cost savings for large-scale AI operations.
Longer context handling: By speeding up the attention mechanism, the algorithm enables AI models to work more efficiently with much longer pieces of text. This could allow for applications that can understand and generate more complex content without slowing down.
Key Techniques
The improvements stem from three main techniques:
First, the algorithm takes advantage of new GPU features that can perform multiple tasks at the same time. This allows it to process data and move it around simultaneously, rather than doing these tasks one after the other. This is achieved through a method called warp-specialization, which efficiently divides tasks among different parts of the GPU.
Flash Attention 3 also mixes two types of math operations – matrix multiplication and softmax calculations – in small chunks. Instead of doing all of one type of math first and then all of the other, it alternates between them in small batches. This might be harder to visualize, but think of it like alternating between stirring and adding ingredients while cooking, rather than doing all the stirring first and then adding all ingredients at once. This approach allows the computer to work more efficiently, using its resources better. For example, this clever scheduling of operations maximizes the GPU’s processing potential.
Finally, the algorithm uses a special technique called incoherent processing. This method works with a form of math that uses less detailed numbers (FP8), which is faster but usually less accurate. To make up for this loss in accuracy, the technique scrambles the data in a smart way. This scrambling helps prevent unusual values from causing big mistakes. As a result, the calculations can be both fast and accurate, even though they’re using less precise numbers.
The impact of these improvements is substantial, the researchers report. In tests using FP16 (16-bit floating-point) precision, Flash Attention 3 achieved speeds of up to 740 teraflops per second on an H100 GPU. When using FP8 precision, it approached 1.2 petaflops per second, with 2.6 times lower numerical error than baseline FP8 attention calculations.
Future Directions — And Limitations
It’s highly probable that these advances could have far-reaching implications for the AI industry. Faster processing times could lead to more responsive AI assistants, more efficient language translation services, and quicker training of new AI models. The ability to handle longer contexts efficiently could improve AI’s understanding of complex documents or conversations, potentially enhancing applications in fields like legal analysis, medical research, or creative writing.
However, it’s important to note that while Flash Attention 3 might represents a significant step forward, it is still primarily a tool for researchers and developers. End users are unlikely to see immediate changes in their AI interactions, but the benefits will likely trickle down as the technology is integrated into various AI systems and applications.
As AI continues to play an increasingly important role in our daily lives, advances like Flash Attention 3 underscore the rapid pace of progress in the field. By pushing the boundaries of what’s possible with current hardware, researchers are paving the way for more powerful, efficient, and capable AI systems in the future.
The code for Flash Attention 3 is available on GitHub, allowing researchers and developers to explore and build upon this technology.
For deeper and more technical detail than this summary can provide, please read the paper on ArXiv.
Researchers in addition to Dao include: Jay Shah, Colfax; Ganesh Bikshandi, Colfax; Ying Zhang, Meta; Vijay Thakkar, NVIDIA and Georgia Tech and Pradeep Ramani, NVIDIA.


