
Insider Brief
- Hexo Labs researchers developed a Self-Improving AI framework that combines agent scaffold updates and model weight updates in a single feedback loop, achieving better results than either approach alone across multiple benchmarks.
- The system improved performance on Chinese legal classification, GPU kernel optimization and single-cell RNA denoising tasks, surpassing previous benchmark results in all three domains.
- The study suggests scaffold updates primarily improve workflows and tool usage while weight updates embed domain-specific knowledge, with the combination producing larger gains than either method independently.
One of artificial intelligence’s longest-running challenges is building systems that can improve both how they operate and what they know without requiring constant human intervention.
A research team now reports that a new approach could shatter that bottleneck.
In a study published on the preprint server arXiv, researchers at Palo Alto-based Hexo Labs describe a framework called Self-Improving AI, or SIA, that combines two previously separate approaches to AI self-improvement. The system not only rewrites and refines the software framework surrounding an AI model but also updates the model’s internal parameters through reinforcement learning, creating what the research team describes as a unified feedback loop for continuous improvement.
The work addresses what the researchers identify as a central constraint — that’s tech speak for “big problem” — in modern AI development. The “humans are the bottleneck” issue is that people remain responsible for nearly every meaningful improvement. Engineers write prompts, design tools, tune workflows, correct mistakes and retrain models. Even many so-called autonomous AI systems still depend on human-designed mechanisms to evolve.
The Hexo Labs study explores whether an AI system can take over more of that process itself.
The implications extend beyond incremental performance gains. If self-improving systems become reliable, researchers could increasingly delegate optimization tasks to AI agents, allowing human developers to focus on new scientific, engineering and commercial frontiers rather than continually refining existing systems.
As the Hexo Labs team write: “Once a self-improving AI system is in place, humans can move on to focus on other frontiers.”
Combining Two Paths to Self-Improvement
According to the study, research into self-improving AI has largely split into two camps. The first camp focuses on improving the “harness” or “scaffold” surrounding a model. This includes prompts, software tools, retry mechanisms, search strategies and output-processing systems. In these approaches, the underlying model remains unchanged while the surrounding infrastructure evolves.
The second focuses on updating the model itself through techniques such as reinforcement learning and test-time training. Here, the model learns from feedback and improves its internal weights, but the surrounding software framework typically remains fixed.
The researchers report that these two approaches have largely developed independently.
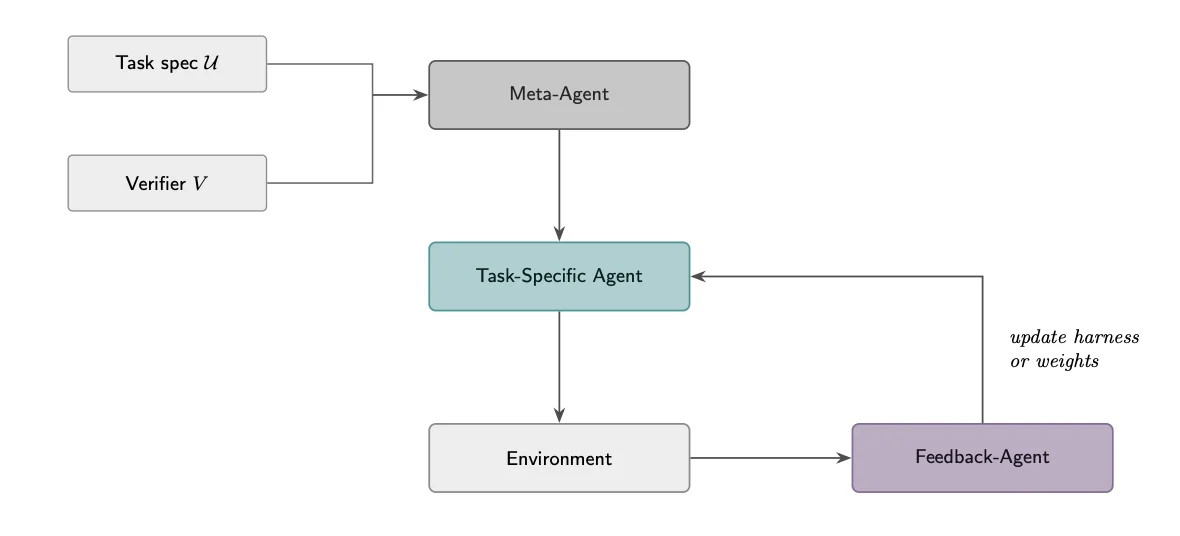
SIA attempts to merge them by employing three AI components. A Meta-Agent creates an initial task-specific agent. That agent performs a task and generates a detailed execution history. A Feedback-Agent then reviews the results and decides whether the next improvement should come from modifying the scaffold, updating the model’s weights, or both. The cycle repeats as performance improves.
The researchers describe this as a two-lever system with one lever changing how the AI works and the other changing what the AI has learned. Previous self-improving systems generally operated on only one of those levers. According to the study, the two mechanisms address different limitations.
Harness updates can improve workflow design, tool usage and error handling. Weight updates can embed domain-specific knowledge directly into the model itself. According to the researchers, neither approach fully substitutes for the other.
Results Across Law, Computing and Biology
To test the concept, the team evaluated SIA on three substantially different tasks.
The first involved Chinese criminal law classification. The benchmark required the system to identify the correct criminal charge from 191 possible categories based on case descriptions. Legal distinctions were often subtle, requiring the model to distinguish among related offenses such as different forms of theft, assault and fraud.
The researchers report that harness improvements alone increased classification accuracy from an initial 13.5% to 50%. After introducing weight updates, performance rose further to 70.1%, exceeding the previous state of the art of 45%.
The second benchmark focused on GPU kernel optimization, a highly technical computing task involving code used in AlphaFold-related protein structure prediction workflows. The challenge required the AI to generate increasingly efficient CUDA kernels for Nvidia H100 graphics processors.
Harness improvements initially produced modest gains. However, once weight updates were introduced, the system achieved substantially faster runtimes, outperforming prior benchmark results and reaching a reported speedup of more than 14 times over baseline performance.
The third benchmark involved denoising single-cell RNA sequencing data, which is an important task in computational biology. Such datasets often contain missing or corrupted measurements and require algorithms to reconstruct underlying biological signals.
According to the study, harness improvements reached a performance plateau. Weight updates subsequently increased reconstruction quality by roughly 20% beyond the harness-only result and exceeded the prior benchmark score.
Across all three domains, the combined approach consistently outperformed harness-only optimization. The researchers report gains of 25.1% above prior state-of-the-art performance on the legal benchmark, 12.4% faster kernel execution on the computing benchmark and 20.4% improvement on the biological benchmark.
What Each Type of Improvement Contributes
One of the main questions the team set out to answer in the study was whether harness updates and weight updates solve different problems.
The researchers report that harness updates primarily produced software-engineering improvements. These included better parsers, improved retry logic, enhanced tool usage and more structured workflows. For example, on the legal benchmark the system built specialized answer-extraction mechanisms and ranking procedures. On the GPU benchmark, it created tools that parsed compiler errors and fed diagnostic information back into subsequent attempts.
These changes improved how the system interacted with its environment.
According to the researchers, reinforcement learning altered the model’s internal representation of domain knowledge. On the legal task, weight updates improved the model’s ability to distinguish among closely related criminal charges. On the GPU optimization task, the model began generating hardware-specific optimization patterns that did not emerge through harness improvements alone.
One of the more striking examples emerged in the biological benchmark. The researchers found that the first weight-updated model added a step to prevent impossible negative gene-expression values. What this likely indicates is that the system had internalized a basic biological rule that earlier software-only improvements never discovered.The harness-only system never generated that modification despite multiple iterations.
The finding suggests that some forms of domain understanding may be easier to internalize through learning than through software modifications.
How the System Learns
The SIA framework does not rely on a single training method, rather the Feedback-Agent selects among several reinforcement-learning approaches depending on the characteristics of the task. These include Proximal Policy Optimization, Group Relative Policy Optimization, entropic advantage weighting, Direct Preference Optimization and other techniques.
The choice depends on factors such as how sparse rewards are, how expensive rollouts become and whether outputs can be scored directly or only ranked relative to one another.
The underlying model used throughout the experiments was GPT-OSS-120B, which was adapted through Low-Rank Adaptation, or LoRA, a technique that modifies a small subset of parameters rather than retraining an entire large model. The researchers report using LoRA rank-32 adapters and conducting training on Nvidia H100 GPUs.
The system’s improvement process also relies heavily on execution histories. Rather than receiving only summary scores, the Feedback-Agent reviews complete trajectories containing prompts, responses, tool calls, outputs and extracted answers. The researchers report that this allows the system to identify specific failure modes and generate targeted improvements.
Limitations and Open Questions
Despite the advances, the researchers acknowledge several limitations and a path toward future research.
One concern involves what they describe as a coupled optimization problem. Because both harness updates and weight updates optimize against the same verifier, the two mechanisms may learn to exploit patterns in the evaluation system rather than develop broadly useful capabilities. Improvements that appear robust during training could prove fragile when conditions change.
The study also evaluates only three benchmark domains. While those tasks span law, computing and biology, broader testing would be needed to determine whether the approach generalizes across a wider range of scientific, engineering and commercial applications.
Another limitation is that the Feedback-Agent itself remains fixed. It decides when to modify scaffolds and when to update weights, but its own decision-making process is not currently learned.
The researchers identify that as a future research direction. They propose training the Feedback-Agent’s action-selection policy through reinforcement learning across many tasks, creating a system that not only improves itself but also improves its own improvement strategy.
They also suggest more tightly interleaving harness modifications and weight updates rather than alternating between them in larger steps. Such an approach could potentially accelerate adaptation by reducing delays between identifying a problem and responding to it.
For Hexo Labs, the study represents an early step toward a larger objective. The Palo Alto company is pursuing an open-source vision of Self-Improving AI in which AI systems increasingly take responsibility for their own development. The research team’s results suggest that improving an AI’s tools and improving its knowledge may be more effective when done together rather than separately.


