
Insider Brief
- Qwen researchers introduced Qwen-AgentWorld, a language-based world model designed to simulate how digital environments respond to AI agents across search, software, terminal, web, mobile and operating-system tasks.
- The study reports that Qwen-AgentWorld outperformed several frontier models on the team’s AgentWorldBench benchmark, with its strongest results in text-based environments and more mixed results in graphical-interface tasks.
- The researchers found that using the model as a simulator or as a training warm-up improved agent performance, while noting limitations including difficult search tasks, imperfect GUI simulation and the need for independent validation.
Qwen researchers say they have built a language-based world model that can simulate how digital environments respond to AI agents, a step that could make it easier to train general-purpose agents without relying only on live software systems.
The study, posted to arXiv, introduces Qwen-AgentWorld, a family of large language models trained to predict the next state of an environment after an agent takes an action. In plain terms, the system tries to act like a simulator for the kinds of places AI agents operate: search engines, terminals, software repositories, mobile apps, websites, desktop operating systems and tool servers.
Qwen is Alibaba’s family of large language models, developed by its Qwen team for tasks including reasoning, coding, tool use and AI-agent development.
The work addresses a growing problem that many current agents are trained to choose actions, such as running a command, clicking a button or calling a tool. But the researchers argue that stronger agents also need to understand what is likely to happen after those actions. That ability, often called world modeling, has long been studied in robotics and reinforcement learning. The Qwen study applies the idea to language-based agent environments, where observations are not physical images but structured text, tool outputs, terminal responses, file contents, accessibility trees and user-interface states.
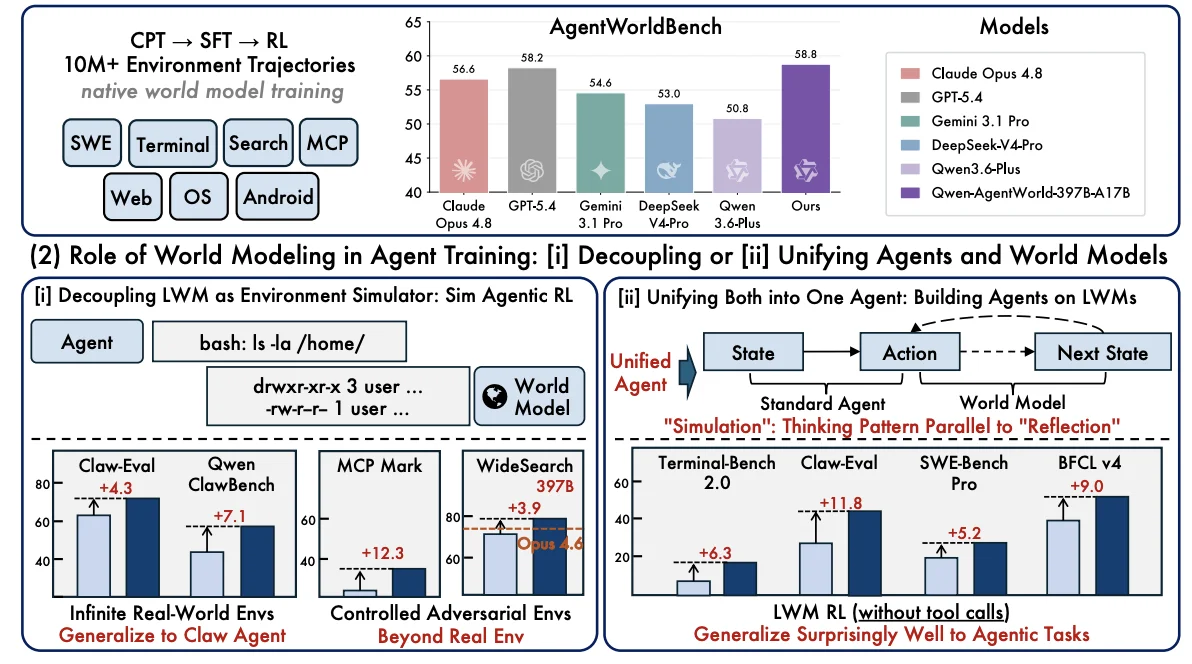
The team presents two model sizes, Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B. The larger model performed best overall in the team’s benchmark, AgentWorldBench, which tests how well models predict real environment responses across seven domains. The benchmark contains 2,170 turn-level samples drawn from real interactions by frontier AI agents on established agent tests, including Terminal-Bench, OSWorld-Verified, WebArena Verified, WideSearch, MCPMark and Tool Decathlon.
A Simulator for AI Agents
According to the study, Qwen-AgentWorld was trained on more than 10 million environment interaction trajectories. These are records of what an agent did and how the environment responded. The researchers converted those records into a shared format across all seven domains, allowing a single model to learn from terminal sessions, software engineering tasks, web navigation, Android actions and tool-use workflows.
The training process had three stages. First, continual pre-training exposed the model to environment dynamics and broad professional knowledge, including material from fields such as cybersecurity, law, medicine, finance and current affairs. Second, supervised fine-tuning taught the model to reason explicitly about next-state prediction. Third, reinforcement learning sharpened the model’s simulation quality using a reward system that combined rubric-based judging with rule-based checks.
The researchers report the result is a model that receives a history of interaction, a current action and a description of the environment, then predicts the next observation. For example, if an agent runs a command in a terminal, the model predicts the terminal output and prompt. If an agent taps a button in an Android app, the model predicts the next screen state as a structured interface representation. If an agent calls an API tool, the model predicts the tool response while maintaining state across turns.
According to the researchers, this matters because real environments can be expensive, slow, risky or hard to reproduce. Search engines change constantly, terminal sandboxes require dedicated infrastructure, business tools may contain private data, and some workflows involve actions that cannot easily be undone. A language world model could give researchers a controlled setting where agents can practice against many more situations than developers could safely or cheaply create in live systems.
Benchmark Results
On AgentWorldBench, Qwen-AgentWorld-397B-A17B achieved the highest overall average score among the models tested, according to the study. The benchmark used five evaluation dimensions, including format, factuality, consistency, realism and quality. Each prediction was compared with a ground-truth observation from a real environment.
The larger Qwen-AgentWorld model scored 58.71 on the overall benchmark average, compared with 58.25 for GPT-5.4, 57.80 for Claude Opus 4.6 and 56.59 for Claude Opus 4.8, as reported in the paper. Its strongest results were in text-based environments, including search, software engineering and terminal tasks. It was more competitive than dominant in graphical interface tasks, where some baseline models remained close or stronger in individual domains.
Search was the hardest domain for all systems with the best search score in the study hitting only 37.82, far below the top scores in software engineering and tool-use domains. The researchers attribute this to the difficulty of modeling changing web content and maintaining factual consistency over long retrieval chains.
The study also tested whether the model learned general world-modeling skills or merely domain-specific patterns. In one experiment, the researchers ran the reinforcement-learning stage only on terminal data, then evaluated performance on other text-based domains. Terminal performance rose by 14.2 points, but the model also improved in held-out areas: software engineering rose by 11.5 points, search by 11.8 points and MCP tool-use by 5.0 points. The team said this suggests the training reinforced general concepts about how environments respond to actions, rather than only memorizing terminal formats.
Training Beyond the Real World
The study suggests Qwen-AgentWorld can be used to train better agents through two main approaches.
In the first, Qwen-AgentWorld served as a separate simulator. A policy agent interacted with the simulated environment, receiving generated observations instead of real ones. The team used this approach to create 4,000 simulated OpenClaw-style environments, based on a small number of real interaction traces. Those environments covered tasks such as scheduling, coding, email triage, browser automation and file management.
Training against the Qwen-AgentWorld simulator improved Claw-Eval performance from 65.4 to 69.7 and QwenClawBench performance from 47.9 to 55.0, according to the study. Using a non-specialized Qwen model as the simulator produced only small gains, which the researchers used as evidence that dedicated world-model training was important.
The researchers also tested controllable simulation, where the world model is instructed to create specific training conditions. In tool-use tasks, it could inject intermittent API errors, partial responses, paginated results or failures in batch operations. These conditions were designed to expose weaknesses that ordinary real-world training might rarely encounter.
In Tool Decathlon and MCPMark, controllable simulation improved Tool Decathlon from 32.4 to 36.1 and MCPMark from 21.5 to 33.8. The uncontrolled simulator did not provide a meaningful gain in Tool Decathlon and produced a smaller improvement on MCPMark.
For search, the team built fictional but internally consistent worlds. These simulated settings contained invented facts arranged in structured databases, documents and search results. Because the facts did not exist in the real world, the agent could not rely on memorized knowledge. It had to learn to search, extract and combine information. In WideSearch, controllable simulation improved the smaller model’s F1 score, a standard measure of how well a system finds the right information while avoiding wrong answers. The score rose from 34.02 to 50.31 at the item level and from 13.72 to 24.21 at the row level.
The researchers compared simulated training with real-environment training using a live search engine. In the first 60 training steps, controllable simulation slightly exceeded real-environment training on WideSearch, reaching 50.3% F1 by item compared with 45.6% for real-environment training. The simulated setup also changed agent behavior: agents trained in the fictional search world used more full-page extraction calls, because the simulator was designed to withhold complete answers from snippets.
World Modeling as Agent Training
The second approach was to use world-model training as a warm-up for the agent itself. Rather than keeping the simulator and agent separate, the researchers trained a model on next-state prediction and then evaluated it directly as an agent on tool-calling tasks.
The gains were broad. Terminal-Bench 2.0 rose from 33.25 to 39.55. SWE-Bench Verified rose from 64.47 to 67.86. SWE-Bench Pro rose from 42.18 to 47.42. WideSearch F1 by item rose from 33.38 to 46.17. Out-of-domain benchmarks also improved: Claw-Eval rose from 53.60 to 64.88, QwenClawBench from 39.76 to 49.43 and BFCL v4 from 62.29 to 71.25.
The researchers interpret this as evidence that next-state prediction works as a transferable reasoning skill. A model that can predict what a terminal, website, tool server or app will do next may be better able to choose useful actions before it takes them.
The study’s analysis supports that idea. In Terminal-Bench 2.0 traces, the researchers found that environment prediction accuracy increased from 69.9% before language-world-model reinforcement learning to 78.3% afterward. In one case study involving a Postfix and Mailman server task, the model trained with world modeling correctly anticipated that a proposed routing fix would fail because recipient validation would occur first. That led it to modify the right configuration and pass the task, while the baseline model pursued ineffective fixes.
- Limitations and Future Work
The study is an arXiv preprint, which means the results have not gone through peer review. Many of the evaluated baseline models and benchmarks are described within the paper’s own experimental framework, so independent replication will matter. The benchmark also relies partly on judge models to score open-ended predictions, though the researchers tried to reduce subjectivity by comparing predictions with ground-truth environment outputs.
The work also shows that world models remain imperfect. Search was difficult for all models. GUI domains remained challenging. Simulation quality depends heavily on a detailed initial state. Without enough information about files, apps, databases, permissions or interface state, a simulator can produce plausible but wrong outputs.
The researchers also note that language-based simulation trades determinism for generality. A code-based simulator can be exact when the environment is fully specified. A language model can cover messier domains, but it may hallucinate, miss hidden state or generate outputs that look realistic without being correct.
The team lists several future directions: co-evolving agents and world models through self-play, adding screenshots to text-based interface representations, learning when to route a task to a simulator or a real environment, and using the world model to synthesize new tools dynamically.


